


| | | Writing a class derived from CEventProcessor |
As with Readout, we will put our additional class code into separate files. This helps make our code re-usable and easily maintained. For example, if our event package is used in a larger experiment, we can just plug it in as an additional event processor.
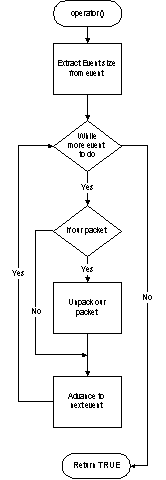
In order to support this when analyzing events, we need to look at the entire event and ignore packets that are not intended for us. A high level flowchart of the unpacking function is shown below in the figure Unpacking Flowchart.
Note how we ignore packet types we don't recognize. This allows us to be inserted into the analysis pipeline without any knowledge of what the other elements of the pipeline are doing. This unpacker needs to have 32 elements of the CEvent array dedicated to it.
In this implementation, we will use a pair of constants, one for base parameter index of the parameters we unpack from the ADC and another for the TDC. The code for the class definition is in, MyEventProcessor.h shown below:
ifndef __MYEVENTPROCESSOR_H
#define __MYEVENTPROCESSOR_H
/*!
Event unpacker for an experiment. The event structure is that
of a documented packet with up to 16 subpackets. The
subpackets contain a phillips tdc and adc channel, and are
also tagged with length and id.
*/
class MyEventProcessor : public CEventProcessor
{
public:
virtual Bool_t operator() (const Address_t pEvent,
CEvent& rEvent,
CAnalyzer& rAnalyzer,
CBufferDecoder& rDecoder);
protected:
void UnpackPacket(TranslatorPointer<UShort_t> p,
Cevent& rEvent);
};
#endif
This header defines a class, MyEventProcessor, and the member function operator() that is called for each physics event. operator() must return a Bool_t (boolean) value. This return value should be kfTRUE if the unpacker succeeded, and kfFALSE if not. If the value returned is kfFALSE, SpecTcl will abandon processing the event. The unpacked parameters will not be histogrammed and no other event processors will be invoked. The function UnpackPacket is a helper function as we will see later.
The parameters passed to operator() are as follows:
| Name | Type | Usage |
| pEvent | Address_t | Pointer to the raw event. |
| rEvent | CEvent | An array like object where parameters get stored |
| rAnalyzer | CAnalyzer | A reference to the analyzer. |
| rDecoder | CBufferDecoder | A reference to the buffer decoder. |
Note that:
The main part of our work in the implementation is to copy selected data words from pEvent into specific elements of rEvent.
The implementation of MyEventProcessor::operator() is shown in the example below:
Bool_t
MyEventProcessor::operator()(const Address_t pEvent,
CEvent& rEvent,
CAnalyzer& rAnalyzer,
CBufferDecoder& rDecoder) [1]
{
TranslatorPointer<UShort_t> p(*(rDecoder.getBuferTranslator()), [2]
pEvent);
CtclAnalyzer& rAna((CTclAnalyzer&)rAnalyzer);
UShort_t nWords = *p++; // Word count.
rAna.SetEventSize(nWords*sizeof(UShort_t)); [3]
nWords--; // Already, we're past the event size.
while(nWords) {
UShort_t nPacketWords = *p;
UShort_t nId = p[1]; [4]
if(nId == nOurId) { // This is our packet!!.
UnpackPacket(p, rEvent); [5]
}
p += nPacketWords; [6]
nWords -= nPacketWords;
}
}
return kfTRUE; [7]
}
Refer to the numbers (like [1]) to match up comments below with corresponding code.
The implementation of UnpackPacket is shown below.
*!
Unpack an event packet we recognize. In a larger system
there might be separate functions, or even separate classes
for each packet recognized.
pEvent points to the packet.
The body of the packet contains 4 word sub packets that contain:
+------------------------------+
| 4 |
+------------------------------+
| Channel number (0-15) |
+------------------------------+ [1]
| TDC Value |
+----------------------------- +
| ADC Value |
+------------------------------+
*/
void
MyEventProcessor::UnpackPacket(TranslatorPointer<UShort_t> pEvent,
CEvent& rEvent)
{
UInt_t nPacketSize = *pEvent;
++pEvent; ++pEvent; // Skip header of packet.
nPacketSize -= 2; // Remaining number of words.
while(nPacketSize) { [2]
UInt_t nSubPacketSize = *pEvent;
++pEvent;
Int_t nChannel = *pEvent; [3]
++pEvent;
rEvent[nTDCBase + nChannel] = *pEvent;
++pEvent; ?
rEvent[nADDBase + nChannel] = *pEvent;
++pEvent;
nPacketSize -= nSubPacketSize; [4]
}
}
Once more, the numbers in the comments below refer to the numbers like: [1] in the sample code.
| | | Writing a class derived from CEventProcessor |